
How to gather email addresses from mail and other data to create a list
A disclaimer, you shouldn’t just add people to a newsletter list indiscriminately. It would be best if you endeavoured to get them to opt-in in every way possible. Another other option sucks. While what I describe is a special case, all the addresses that I extracted were used to solicit opt-ins.
Right, so my problem here was that a client asked needed to extract data from a few disparate sources and build a clean, usable list of email addresses. Certainly, no small feat since some of this would have to come out of an email account itself. I wasn’t even going to benefit from working from contacts either – addresses had to come from the messages themselves. I’m going to describe what I did to get there.
Also, this only relates to work with data locally. This does not describe scraping email addresses off websites, etc. That may be another challenge for another day.
#1 – Get the data local to you on the machine. I chose to use Microsoft Outlook because, well, it’s what I had around. Suppose you have a mail client that stores its mail data in plain text (props to the old school Eudora), all the better. In my case, I hooked Outlook into the customer’s account and engaged a nearly 10GB download of mail data.
Other information would come in via an Excel spreadsheet and a rather haphazard text file listing some email addresses.
#2 – Set this data in text format. So, for Outlook, I’d select about 40,000 messages and export them as CSV files. You end up with some gnarly shit here, but the files are at least reasonably sized and in text. Using Outlook, it crashed a few times, and when it didn’t crash, I had to kill it and restart after every export anyway.
Any other binary data also need to get moved to text. So for an Excel file, export that as CSV. For already text-based stuff, leave it alone. If you also have email addresses in image format, use an OCR tool to extract that text data. Tesseract might do the trick for you.
#3 – Extract the email addresses from this mass of text files. I used the application called eMail Extractor, but you can use what you like in this case. Be wary of an online tool as this should probably happen offline (don’t give these addresses to anyone). I’m not really wedded to any tool at this stage, so long as it gets the email data out. Adding the text files one at a time in 60MB (or less) increments generally works. If you do it all on one pass, you’ll have a reasonably good list of non-duplicates.
#4 – Do a final pass to sanitize the list. In this stage, I took the results.csv provided by eMail Extractor and opened it. For this, I used the incredibly useful editor Notepad++ one feature, particularly the bookmarking feature. Using this, you can reasonably quickly get rid of non-usable addresses.
a) Scroll through the messages slowly and pick up on a pattern. An easy one might be the derivatives of “no-reply.” For each term, open the find window and enable “Bookmark Line” – this will place a blue ball to the left of the bookmarked lines.
b) Close the Find window and then choose from the menu Search -> Bookmark -> Remove Bookmarked Lines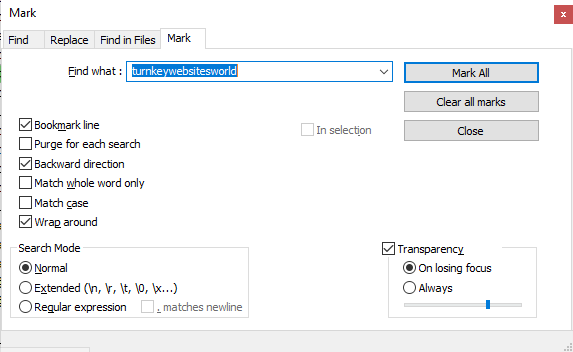
Go through these steps looking for any pattern that might include spam, botnet, inactive or otherwise addresses, whittling the list down as much as possible. You can even go after terms like “lust” or. “@” or even “.ip.” to track down unusual stuff. Using the base of addresses in front of you, search and destroy everything that seems out of place.
Using this method, I took about 10.5 gigabytes of messages, 1 million extracted email addresses (including duplicates) and whittled that down to about 16,000-odd addresses that could be used as a mailing list base or a newsletter.
And note, you could indeed continue this further using regular expressions to get the list cleaner. There may be an online clearinghouse of expressions to filter dirty or bot mail addresses – if you know about one, do share.